Machine Learning -關聯分析-Apriori演算法-詳細解說啤酒與尿布的背後原理 Python實作-Scikit Learn一步一步教學
Yo, 今天來跟大家介紹一個非常有趣的分析方法-關聯分析(Apriori),為什麼說它有趣呢?因為它是在擁有大量數據的資料庫中,找尋資料間彼此的關聯, 很常會讓人意想不到!!經典的Walmart 尿布與啤酒的故事,這兩樣八桿子打不著關係的商品放在一起,竟然可以增加營業額!!這就是使用關聯分析所發現的喔!!
1. 關聯分析是什麼?
a. 簡單來說,它就是在大量數據中找尋資料彼此之間的關聯,它是透過兩種主要的方式來進行分析: 頻繁項集、關聯規則
i. 頻繁項集(Frequent Itemsets): 經常一起出現的物品集合
ii. 關聯規則(Association Rules): 表達數據之間的可能存在很強關聯姓
b. 分析主要透過計算支持度(Support)與信心水準(Confidence)來挖掘數據間關聯的強弱
c. 舉例: 如圖中,我們可以看出{B、C、E}這三項物品一起出現的頻率高,也就是所謂的頻繁項集,而圖中也可以尋找{B、E}這兩箱物品一起出現的關聯,就稱為關聯規則,而它們關聯的強弱就由支持度(Support)與信心水準(Confidence)來計算

d. 應用範例: 關聯分析使用的範圍相當廣,也是非常受到歡迎的分析方法, 這邊就舉幾個社會上的使用案例: 1. 淘寶推薦相關書籍 2. 百度文庫推薦相關文件 3. Walmart尿布與啤酒 4. 推薦醫療器具組合
2. 歷史回顧
a.關聯分析觀念提出者: Agrawal, Imielinski and Swami於SIGMOD會議上所提出(1993) b. Apriori演算法提出者: Agrawal and Srikant(1994)提出執行關聯分析的演算法
3. 關聯規則的重要評估指標
a. 支持度(Support):
表示物品集(Ex. 如果只有一個物品({A),如果有想個物品{A,B})在擁有N個資料(ALL_DATA)的數據庫中出現的次數比例
公式: i. 只算一個物品出現的支持度: Support(A) = Count(A)/Count(ALL_DATA) ii. 兩個物品同時出現的支持度時: Support(A -> B) = Count(A ∪ B) / Count(ALL_DATA)
舉例: 如果總共的交易數據有200筆, 香腸這項商品出現的次數有20筆, 那它的支持度為50/200 = 1/4, 也就是香腸的支持度為25%
b. 信心水準(Confidence):
表示兩物品同時出現的條件機率,簡單來說就是在已經出現商品A的情況下,出現商品B的機率
公式: Confidence(A -> B) = P(B|A) = P(A ∪ B) / P(A)
c. 提升度(Lift):
表示當經出現商品A的情況下,出現商品B的機率,但會看出只出現商品B的機率的問題,提升度(Lift)代表著數據間的關聯性
公式: Lift(A -> B) = Confidence(A -> B) / P(B) = P(B|A) / P(B)
i. 提升度 > 1 : 表示數據間越相關,呈正相關
ii. 提升度 = 1 : 表示兩數據獨立,不相關
iii. 提升度 < 1 : 表示兩數據呈負相關
d.其他指標: Leverage 和 Conviction
這兩個指標比較不會用到,但是這邊還是跟大家提一下,它們兩個都是值越大表示關聯越強
公式: Leverage: P(A,B)-P(A)P(B) Conviction: P(A)P(B)/P(A,B)
補充: 支持度(Support)跟信心水準(Confidence)就可以計算了,為什麼要使用提升度? 因為有能會有在有A商品的情況下,有B商品的機率高, 但在沒有A商品的情況下,有B商品的機率還是很高,但如果忽略掉提升度(Lift)就會誤判,以為A->B的關聯性很強
4. 進行關聯分析前的預備
a. 在進行關聯分析前,我們要先設定好我們的最小支持度(Min Support)與最小信心水準(Min Confidenc),這需要自行定義,那我通常會定義在50%,也就是說商品項目集{A,B}的# 支持度要高於50%,也就是出現次數要高於(總共數據量 x 50%)次, 才為高頻率項集,如果低於這個次數,就會被拿掉不考慮, 下面的Apriori原理中會做詳細介紹
b. 設定太高或太低? 設定太低的話,會導致關聯分析的結果出現太多的關聯規則,太高的話,關聯規則太少, 都不利我們參考分析結果做決策
5. Apriori優缺點:
缺點: 1. 資料量大時, 運算效率低
優點: 1. 數據中只需要有關連數據即可,其它屬性資料用不到 2. 容易編碼
6. Apriori原理
Apriori重要假設: Apriori是計算頻繁項集的一種演算法,它假設當項集是頻繁的,也就是假設B這個物品在數據中是頻繁出現的,那它的子集也會是頻繁的,也就是說{B、C}、{B、C、E}等也是頻繁的,反之就是不頻繁的
這邊使用圖片來為大家講解Apriori的原理
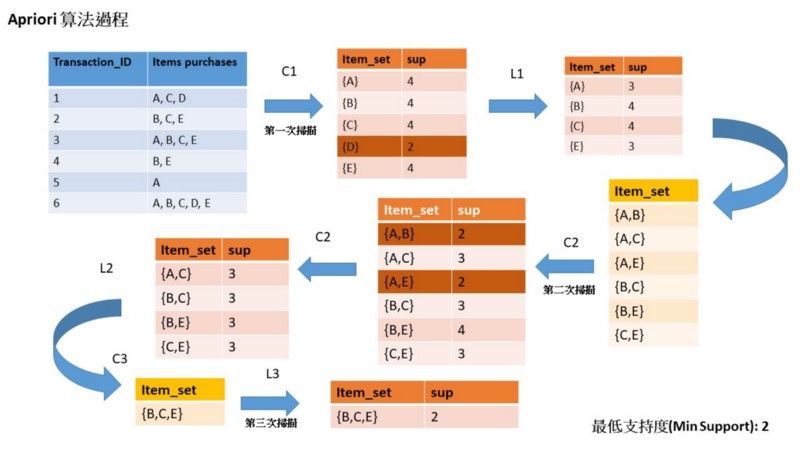
Step1: 上圖由左至右進行疊代,有了最左邊的數據庫後,接下來進行第一次掃描,可以看出每樣商品出現的次數,由於我們自行設定的最小支持度為50%,所以如果次數小於3(總數據量6 x 50%),就會被當成是不頻繁項集淘汰,也就是圖中的D商品,為什麼會被淘汰?因為前面有提到Apriori的重要假設,當項目集是不頻繁的,那它的子集也不會頻繁,接下來就形成了新的數據表
Step2: 接下來進行我們的第二次掃描,也就是項目集中會有兩樣商品來做分析,一樣列出出現次數後,淘汰掉次數低於3的項目集,形成新的數據表
Step3: 最後進行我們的第三次掃描,項目集中會有三樣商品來做分析,列出出現次數,由於只有一組項目集,分析過程也就完成囉,最後一樣會形成一個關聯數據表
7. 實作
這邊我放了兩種實現Apriori算法的方法,更多的方法我會放在我的Github中,歡迎大家自行參考
方法一: 使用apyori套件
Step1: 安裝套件
pip install apyori
Step2: 程式實作
a. 調整最小支持度(Min Support)、最小信心水準(Min Confidence)、最小提升度(Min Lift)來實現你的關聯分析,最小提升度要大於1才有關聯,所以要設在1以上,越大表示關聯性越強
b. max_length: 用來調整要對幾個商品關聯, 拿下面的程式碼來看,如果改成max_length = 4,那print(pair)就會有二到四個商品在list中,也就是我們剛剛學習過的原理,它會繼續scan下去,直到項目集裡有四個商品
## Import package
from apyori import apriori
## Data 自行定義數據
market_data = [['T-Shirt','Pants','Jeans','Jersy','Socks','Basketball','Bottle','Shorts'],['T-Shirt','Jeans'],['Jersy','Basketball','Socks','Bottle'],['Jeans','Pants','Bottle'],['Shorts','Basketball'],['Shorts','Jersy'],['T-Shirt'],['Basketball','Jersy'],]
association_rules = apriori(market_data, min_support=0.2, min_confidence=0.2, min_lift=2, max_length=2)
association_results = list(association_rules)
##print(association_results )
for product in association_results:#print(product) # ex. RelationRecord(items=frozenset({'Basketball', 'Socks'}), support=0.25, ordered_statistics=[OrderedStatistic(items_base=frozenset({'Basketball'}), items_add=frozenset({'Socks'}), confidence=0.5, lift=2.0), OrderedStatistic(items_base=frozenset({'Socks'}), items_add=frozenset({'Basketball'}), confidence=1.0, lift=2.0)])pair = product[0]
##print(pair) ## ex. frozenset({'Basketball', 'Socks'})products = [x for x in pair]print(products) # ex. ['Basketball', 'Socks']print("Rule: " + products[0] + " →" + products[1])print("Support: " + str(product[1]))print("Lift: " + str(product[2][0][3]))print("==================================")

方法二: 使用mlxtend套件,將數據轉換成one-hot編碼
這個方法中,在最後計算關聯規則(Assocaition Rules)的同時,會幫我們計算各種指標值,像是我們之前有提到的Conviction與Levrage也會呈現出來
Step1 : 安裝套件
pip install mlxtend
Step2: 程式實作
## Import Package
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
## Data 自行定義數據
market_data = {'Transaction ID': [1,2,3,4,5,6,7,8],'Items':[['T-Shirt','Pants','Jeans','Jersy','Socks','Basketball','Bottle','Shorts'],['T-Shirt','Jeans'],['Jersy','Basketball','Socks','Bottle'],['Jeans','Pants','Bottle'],['Shorts','Basketball'],['Shorts','Jersy'],['T-Shirt'],['Basketball','Jersy'],]}
## 轉成DataFrame
data = pd.DataFrame(market_data)
## 讓DataFrame 能呈現的寬度大一點
pd.options.display.max_colwidth = 100
## 轉成數值編碼,目前都是字串的組合
data_id = data.drop('Items', 1)
data_items = data.Items.str.join(',')
## 轉成數值
data_items = data_items.str.get_dummies(',')
## 接上Transaction ID
data = data_id.join(data_items)
## 計算支持度 Support
Support_items = apriori(data[['T-Shirt','Pants','Jeans','Jersy','Socks','Basketball','Bottle','Shorts']], min_support=0.20, use_colnames = True)
## 計算關聯規則 Association Rule
Association_Rules = association_rules(Support_items, metric = 'lift', min_threshold=1)
Association_Rules
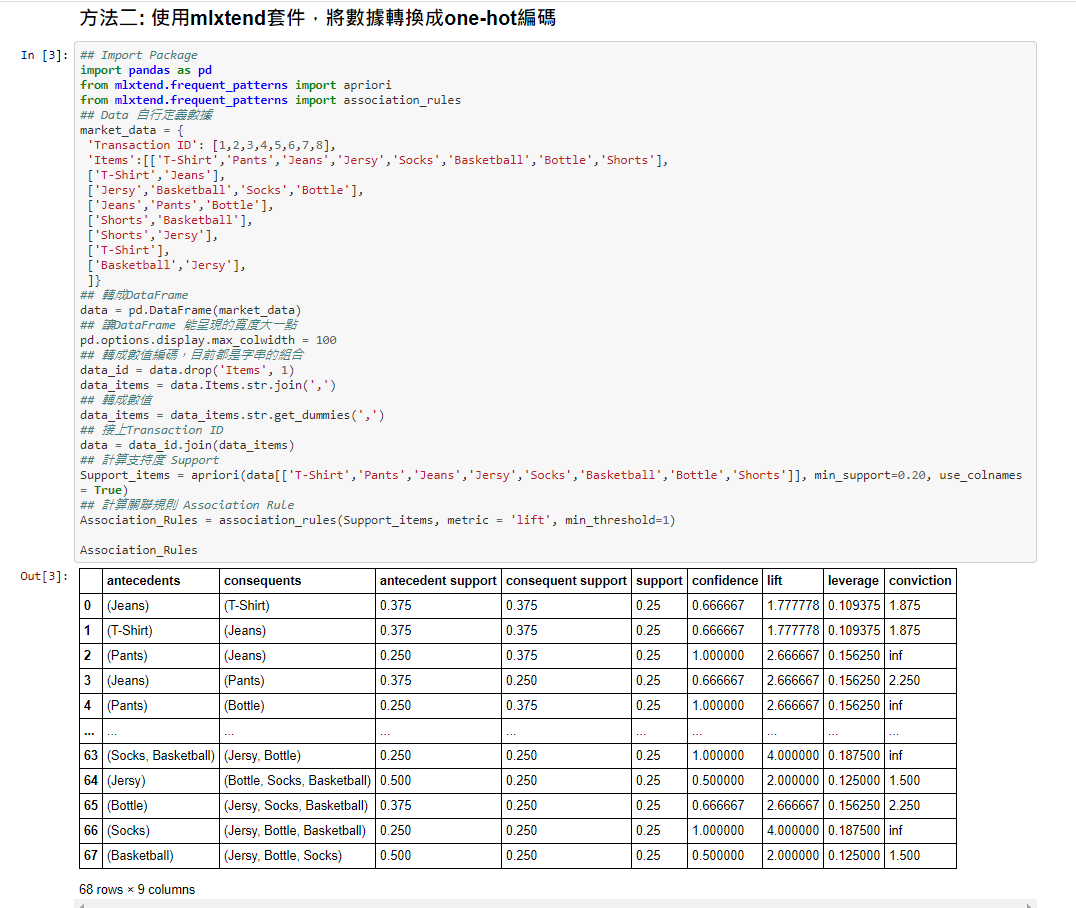
因為排版的關係,我自己也覺得程式不是很清楚,所以大家可以直接去我的Github中看喔!!
學完後是不是覺得很有趣呢?希望大家都有滿滿的收穫~~
Reference:
https://kknews.cc/zh-tw/news/pqnq86e.html
手把手程式實作分享系列:先驗演算法(Apriori Algorithm) 關聯規則分析
0. 前言medium.com
一步步教你輕鬆學關聯規則Apriori演算法
摘要:先驗演算法(Apriori…www.itread01.com
你怎麼處理顧客交易資訊?Apriori演算法
在電腦科學以及資料探勘領域中,Apriori 演算法是「關聯規則學習」或是「關聯分析(Associative…medium.com