給自己的Python筆記-功能強大的缺失值處理方法- DataFrame中的缺失值如何使用插值的方法來填充 - pandas.DataFrame.interpolate() 使用筆記
Github連結

1.插值方法?
- 說明: 插值又稱為內插, 為一種透過已知的離散數據點, 在範圍內推算出新的數據點的方法
- 用法: 透過計算函數在已知點的取值狀況, 估算出函數在其它點處的近似值, 這樣就能用已知的數據來估算出那些未知的數據
- 與機器學習擬和的不同: 插值法計算出的函數所繪出的擬和曲線通過所有已知點
2. DataFrame.interpolate() 參數介紹
函數
interpolate (self, method='linear', axis=0, limit=None, inplace=False, limit_direction='forward', limit_area=None, downcast-None, **kwargs)
參數
- method:使用的插值技術, 預設為"linear' ,可用選項:
- 'linear': 忽略索引, 並將值等距的對待,是Mulitilndex(多重索引)唯一支持的方法
- 'time': 處理每日和更高分辨率的數據, 以給定的時間間隔長度來進行插值
- 'index'、'values': 使用索引的實際數值
- 'pad': 使用現有值填寫NaN
- 'nearest', 'zero', 'slinear', 'quadratic', 'cubic', 'spline', 'barycentric', 'polynomial': 傳遞給scipy.interpolate.interpld,這些方法使用數值的索引值,'polynomial'和'spline都要求您還可以指定一個order (int),例如df.interpolate (method ='polynomial order = 5)
- 'krogh', 'piecewise_polynomial', 'spline', pchip', akima': 包裝圍繞類似的SciPy插值方法名稱
- 'from_derivatives': 指scipy.interpolate.Bpoly.from_derivatives取代了" piecewise_polynomial"插值方法
- axis:沿軸進行內插,1:沿列,0:沿行,預設為None
- limit: 進行插值的最大連續NaN數,一定要大於0
- inplace: 傳入True/False,預設為False,如果設定True,就會盡可能的更新數據
- limit_direction: 選項有'forward', 'backward', 'both',預設為"forward",如果設定limit 就會依照這邊設定的方向填充連續的NaN
- limit_area: 選項有None, 'inside', 'outside',預設為None,當設定limit時,對插值的限制
- None: 沒有填充限制
- 'inside': 僅填補有效值(interpolate)包圍的NaN
- 'outside': 僅在有效值以外(extrapolate)填充NaN
- downcast: 選項有'infer'或None,None是預設,如果可能,請向下轉换dtypes
- **kwargs:關鍵字參數傳遞給插值函數
實作
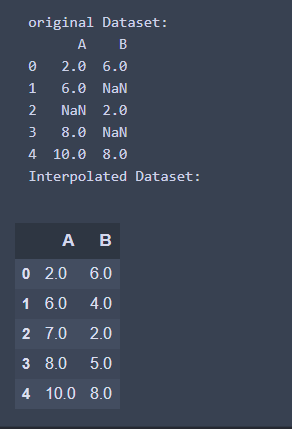
1. 基本插補 -將所有NaN進行内插
import pandas as pd
import numpy as np
## 創建數據集
df = pd. DataFrame({
'A': [2, 6, None, 8, 10],
'B': [6, np.nan, 2, None ,8]
})
print('original Dataset: ')
print(df)
## 進行插值
interpolate_df = df.interpolate()
print('Interpolated Dataset: ')
interpolate_df
執行結果
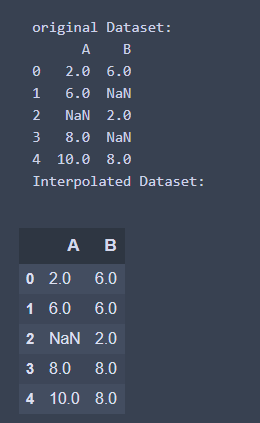
2. 使用Method函數來指定內插的方法
- 這邊以pad('pad': 使用現有值填寫NaN)方法來實作
import pandas as pd
import numpy as np
## 創建數據集
df = pd. DataFrame({
'A': [2, 6, None, 8, 10],
'B': [6, np.nan, 2, None ,8]
})
print('original Dataset: ')
print(df)
## 進行插值
interpolate_df = df.interpolate(method = 'pad')
print('Interpolated Dataset: ')
interpolate_df
執行結果
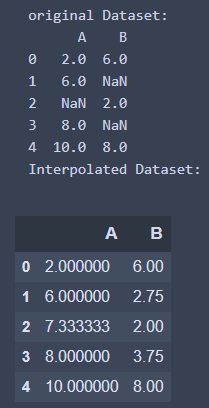
- 這邊以Polynomial方法來實作 - 使用二階多項式的插值方法
order = 2 為Polynomial方法(函數)的關鍵字引數(參數)
import pandas as pd
import numpy as np
## 創建數據集
df = pd. DataFrame({
'A': [2, 6, None, 8, 10],
'B': [6, np.nan, 2, None ,8]
})
print('original Dataset: ')
print(df)
## 進行插值
interpolate_df = df.interpolate(method = 'polynomial', order = 2)
print('Interpolated Dataset: ')
interpolate_df
執行結果
3. 使用limit參數來限制填補的最大連續數量
import pandas as pd
import numpy as np
## 創建數據集
df = pd. DataFrame({
'A': [2, 6, None, 8, 10],
'B': [6, np.nan, np.nan, None ,8]
})
print('original Dataset: ')
print(df)
## 進行插值
interpolate_df = df.interpolate(limit = 1)
print('Interpolated Dataset: ')
interpolate_df
執行結果
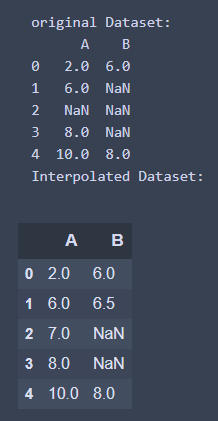
4. 根據哪個方向進行最大的連續填補數量 - limit_direction
- 從後面開始內插
import pandas as pd
import numpy as np
## 創建數據集
df = pd. DataFrame({
'A': [2, 6, None, 8, 10],
'B': [6, np.nan, np.nan, None ,8]
})
print('original Dataset: ')
print(df)
## 進行插值
interpolate_df = df.interpolate(limit_direction = 'backward', limit = 1)
print('Interpolated Dataset: ')
interpolate_df
執行結果
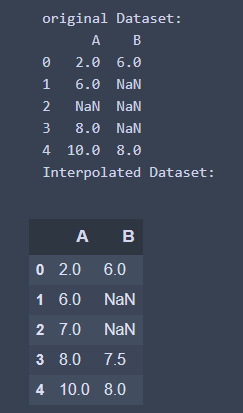
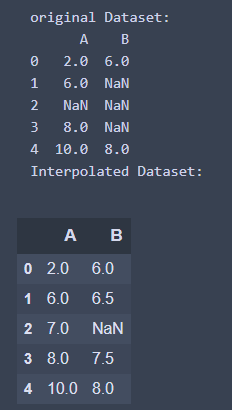
- 從兩邊的中間位置開始進行內插
import pandas as pd
import numpy as np
## 創建數據集
df = pd. DataFrame({
'A': [2, 6, None, 8, 10],
'B': [6, np.nan, np.nan, None ,8]
})
print('original Dataset: ')
print(df)
## 進行插值
interpolate_df = df.interpolate(limit_direction = 'both', limit = 1)
print('Interpolated Dataset: ')
interpolate_df
執行結果
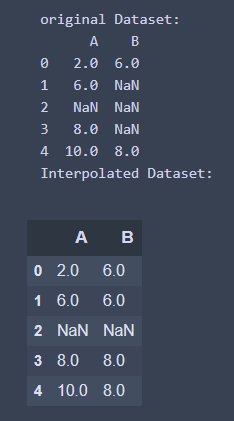
5. 沿著行或列進行內插 - axis
import pandas as pd
import numpy as np
## 創建數據集
df = pd. DataFrame({
'A': [2, 6, None, 8, 10],
'B': [6, np.nan, np.nan, None ,8]
})
print('original Dataset: ')
print(df)
## 進行插值
interpolate_df = df.interpolate(axis = 1)
print('Interpolated Dataset: ')
interpolate_df
執行結果
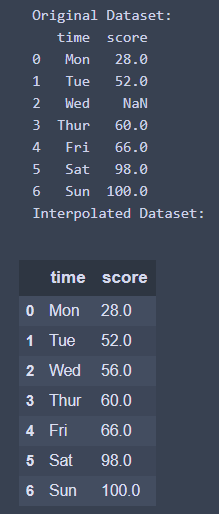
6. 對時間序列型(Time-Series)的數據集進行內插
注意: 當我們要使用inplace參數時,因為它會盡可能的更新數據集,所以只要使用df.interpolate(inplace = True),不用再寫成interpolate_df = df.interpolate(inplace = True),不然會顯示不出資料
import pandas as pd
import numpy as np
## 創建數據集
time = ['Mon', 'Tue', 'Wed', 'Thur', 'Fri', 'Sat', 'Sun']
score = [28, 52, np.nan, 60, 66, 98, 100]
df = pd.DataFrame({ 'time': time, 'score': score})
print('Original Dataset: ')
print(df)
## 進行插補
df.interpolate(inplace = True)
print('Interpolated Dataset: ')
df
執行結果