Machine Learning - 資料前處理 Data Preprocessing - 機器學習筆記 - 如何刪除低方差 的特徵? 如何自行定義閾值? - Sklearn VarianceThreshold套件 - 使用教學...
Github連結

1. 為什麼要刪除低方差的特徵?
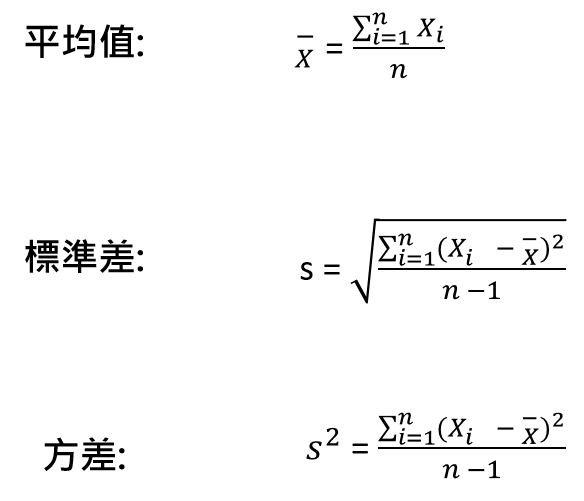
這是因為當有個特徵裡面的值有很多是一樣的時候,大家還會認為這個特徵作用很大嗎?假設我們今天有個特徵裡面只包含0和1的值,而0佔了這個特徵95%的數量,也就是特徵中有95%的值是一樣的,那很明顯這個特徵對我們要進行分析結果的作用不大,更不用說如果全部都是0那這個特徵就根本沒意義了
方差公式
2. 使用時機?
特徵值為離散型的數據時,適合使用這個方法,如果為連續型,那最好將它轉成離散型再使用,可以幫助我們刪除掉那些值變化很小的特徵
3. VarianceThreshold 說明
- 說明: sklearn中feature_selection裡的VarianceThreshold是一種特徵選擇的方法,也是在做前處理時非常有用的功能
- 功能: VarianceThreshold會幫助我們刪除掉那些方差未達到指定閾值的特徵,預設情況下,它會刪除掉所有方差為零的特徵,也就是值都為一樣的特徵
4. 參數、屬性、方法介紹
參數
- threshold: 傳入浮點數,預設為0,當訓練集中低於這個閾值的特徵將被刪除,預設為保留方差不為零的特徵,也就是刪除所有值一樣的特徵
屬性
- variances: 個體特徵的方差(差異)
方法
- fit(X[y]):從X了解經驗方差
- fit_transform(X[y]): 擬和數據,然後對其進行轉換
- get_params([deep]): 獲取此估計量的參數
- get_support([indices]): 獲取所選特徵的掩碼或整數索引
- inverse_transform(X): 反向轉換操作
- set_params(**params): 設置此估算器的參數
- transform(X): 将X縮小為選定的特徵
5. 實作
導入VarianceThreshold套件
## VarianceThreshold from sklearn.feature_selection import VarianceThreshold
預設方法: 刪除所有一樣值的特徵
## 創建數據集
x = [[2, 8, 7, 9], [3, 8, 6, 8], [7, 8, 10, 10]]
print('Before: ', x)
selector = VarianceThreshold()
print('After:')
print(selector.fit_transform(x))
print('Variance: ', selector.variances_)
執行結果
Before: [[2, 8, 7, 9], [3, 8, 6, 8], [7, 8, 10, 10]] After: [[ 2 7 9] [ 3 6 8] [ 7 10 10]] Variance: [4.66666667 0. 2.88888889 0.66666667]
- 原數據集的第二個特徵(列)值都為8,所以在结果中被拿掉了
布林數據中,刪除0或1其中之一出現機率大於80%的特徵
- 如果我們要刪除0或1其中之一出現機率大於80%的特徵,而布林特徵是伯努力隨機變量,所以方差為 Var[X] = p(1 - p)
- 閾值: 0.8*(1 - 0.8)
## 構建數據集
x= [[0, 1, 0, 1], [1, 0, 1, 1], [0, 0, 1, 1], [1, 0, 1, 0]]
print('Before: ', x)
selector = VarianceThreshold(threshold = (0.8 * (1 - 0.8)))
print('After:')
print (selector.fit_transform(x))
執行結果
Before: [[0, 1, 0, 1], [1, 0, 1, 1], [0, 0, 1, 1], [1, 0, 1, 0]] After: [[0 1 0 1] [1 0 1 1] [0 0 1 1] [1 0 1 0]]
如果想將過濾訓練集的結果直接應用到測試集
import pandas as pd ## 創建數據集 - 訓練集與測試集 a = [[2, 8, 7, 9], [3, 8, 6, 8], [7, 8, 10,10]] b = [[3, 3, 7, 9], [4, 2, 6, 10], [8, 4, 2, 101]] x_train = pd.DataFrame(a, columns = ['A','B', 'C', 'D']) x_test = pd.DataFrame(b, columns = ['A','B', 'C', 'D']) selector = VarianceThreshold() ## 擬和訓練集,在轉換到測試集 selector.fit(x_train) selector.transform(x_test)
執行結果
array([[ 3, 7, 9], [ 4, 6, 10], [ 8, 2, 101]], dtype=int64)
- 結果可以看出,在訓練集中第二個特徵被濾掉了,所以轉換到測試集的時候,儘管測試集的第二個特徵值沒有都一樣,還是被濾掉了
6. 遇到一個大問題?特徵的名稱不見了!!怎麼保留特徵?如何反推原數據?
## 創建數據集 - 訓練集與測試集
a = [[2, 8, 7, 9], [3, 8, 6, 8], [7, 8, 10, 10]]
b = [[3, 3, 7, 9], [4, 2, 6, 10], [8, 4, 2, 10]]
x_train = pd.DataFrame(a, columns = [ 'A', 'B', 'C', 'D'])
x_test = pd.DataFrame(b, columns = ['A', 'B', 'C', 'D'])
selector = VarianceThreshold()
## 擬和訓練集,在轉換到測試集中
selector.fit(x_train)
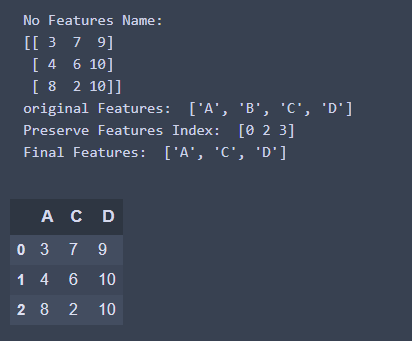
print('No Features Name: ')
print(selector.transform(x_test))
## 保留特徵名稱
features_name = x_train.columns.values.tolist()
print('original Features: ', features_name)
## 被留下來的特徵索引
preserve_feature_index = selector.get_support(indices = True)
print('Preserve Features Index: ', preserve_feature_index)
result_features = []
for i in preserve_feature_index:
result_features.append(features_name[i])
print('Final Features: ', result_features)
## 组合成最終結果
pd.DataFrame(selector.transform(x_test), columns = result_features)
執行結果