輝達能站在AI浪頭上多久-焦點媒體深讀 #23
一、輝達會像2000年的思科曇花一現嗎?
雖然輝達在美國時間6月18號曾短暫站上全世界市值最大的公司後便連跌三天,跌掉了4300億美金的市值,但該公司的股價長期的動向還是要從產業面的發展狀況作為判斷的依據是比較準確的,因此本文會結合《金融時報》關於輝達最新的專題報導和彭博新聞對於AI產業接下來各巨頭的投資狀況描繪出一個較完整的圖像。
從ChatGPT自2022年11月問世以來,對於被臉書、微軟等巨頭認為是打造大型人工智慧系統最好用的圖像處理晶片(GPU)的需求暴漲已經讓輝達的股價漲了7倍之多。不過在站上全球最有價值公司才幾天就跌回第三名顯示了在這個新科技領域有多競爭。輝達能竄起的主旋律是人工智慧經濟:人工智慧經濟的爆炸性成長、對投資人的吸引力還有人工智慧難以預測的未來。到底輝達接下來會如何也是經濟的前景所在,甚至可以說輝達的命運就決定了接下來的經濟前景。
上一次另一家像輝達一樣大家並不熟悉的公司站上全世界市值最大的公司發生在2000年3月,當時生產網路設備的思科市值超越了微軟站上網路泡沫的頂端。今天的輝達和當年思科同樣面對的是大公司都把數十億美金投進即將在計算力以及世界經濟領域發生的新革命的基礎建設上。就像現在的輝達,思科靠賣給所有要在網路上大展身手的企業數位鏟子而發了大財,但它的股價在2000年網路泡沫破裂之後再也回不到高峰。而現在科技巨頭對人工智慧的資本支出急升是基於對人工智慧產業的營收預估而不是實際的收益讓人擔心歷史會不會重演。

2000年短暫成為市值世界第一的思科
所以對知名顧問公司Bernstein的分析師Stacy Rasgon來說這種憂慮可以理解,畢竟當年思科是為了他們希望會實現的需求而擴張產能,但到了今天都還有一些光纖埋在地下根本沒有用到。不過Rasgon又提醒和思科在網路泡沫高峰時的股價比起來,輝達股價相對於其預估的營收並沒有到很高。而像微軟這樣的公司已經有在AI方面的投資收入進帳,不過其他像是臉書則認為還需要更久才會有營收產生。不管怎麼樣,Rasgon認為即使有個人工智慧泡沫正在醞釀,這泡沫也不是很快會破掉。
而思科在網路第一個黃金時代的起落和蘋果、微軟形成明顯對比。這兩家巨頭爭奪市值冠軍寶座已經很多年,靠的不只是創造出非常成功的產品,還靠打造出支持廣大商業生態系統的平台。蘋果曾統計過有在蘋果商店有大約200萬個應用程式,每年為這些應用程式開發者產生幾千億美金的收入。
而輝達為中心所創造的經濟和蘋果周遭所打造出來的看來很不一樣。大致上過去幾個月輝達股價的飆升都是來自於單一應用程式-所帶動的投資。輝達表示在它打造的軟體生態系中有大概四萬家公司還有3700個靠圖樣處理器加速的應用。但輝達是靠賣數量相對少很多(和賣給大眾的幾億個電子產品比起來)的昂貴AI晶片給主要是少少幾家公司所營運的資料中心而短暫成為市值最大的公司。
輝達上個月自己曾指出打造巨型雲計算中心的巨投如微軟、亞馬遜和谷哥就佔了輝達幾乎一半的營收。根據晶片諮詢公司TechInsights的資料,輝達去年賣了376萬片圖像處理晶片給資料中心。這讓輝達拿下在這個專門性的行業中拿下72﹪的市佔率,把對手超微和英代爾遠遠拋在後頭。而且它的營收還在快速增長中。到四月為止的最新一季和去年同期相比營收成長了262﹪,這比蘋果剛推出iPhone時成長的還要快。
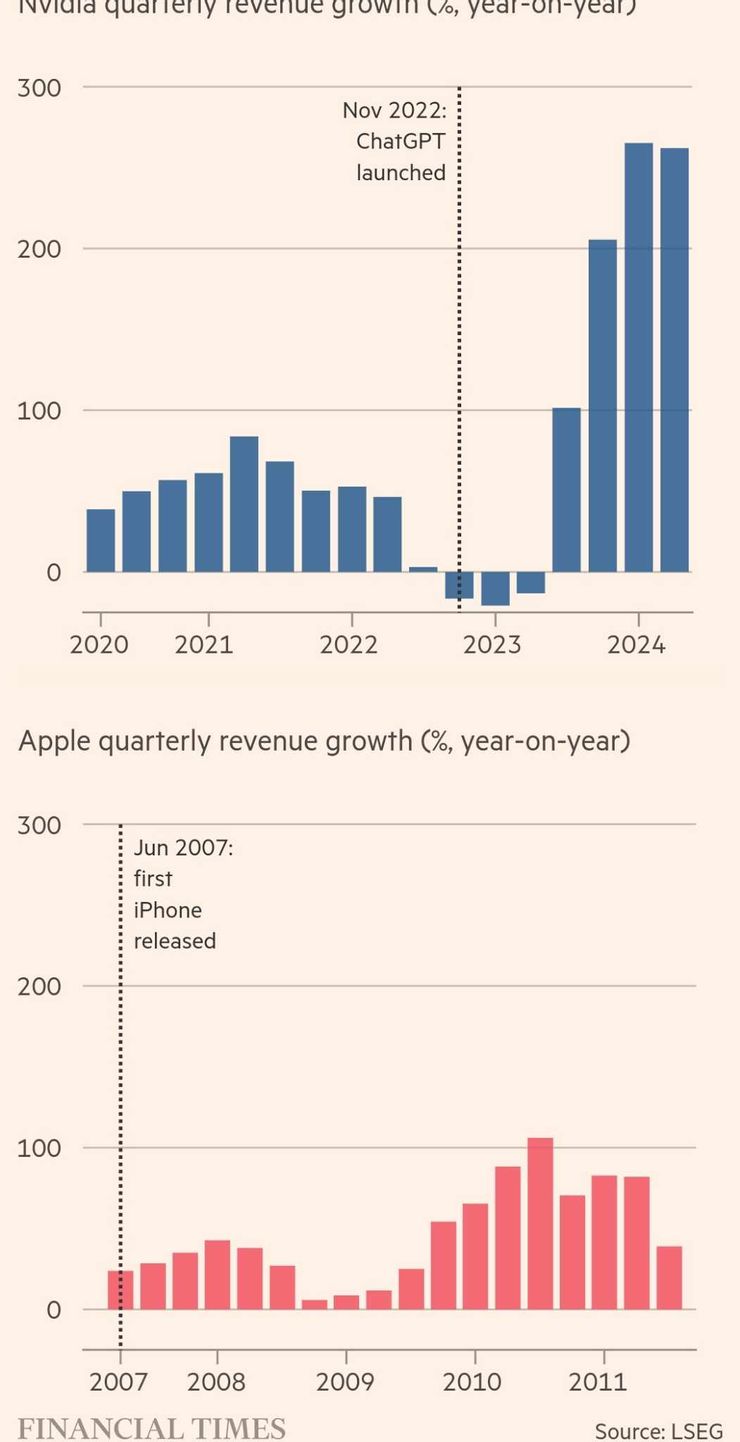
輝達和當年剛推出的iphone的蘋果營收比較
對輝達產品的需求來自於想靠用更多晶片來解決對人工智慧能力質疑的各家科技公司。為了要在人工智慧產生出下一次的大躍進,像是OpenAI、微軟、臉書和馬斯克的新創xAI都在競相建造把十萬個AI晶片連進超級電腦的資料中心,這個規模比現在最大的超級電腦群還要大上三倍。像這樣的伺服器農場光硬體就要花掉40億美金。
而且擁有更多人工智慧計算力的渴望不會消逝。黃仁勳自己預估未來幾年會有一兆多美金投入在現有的資料中心和打造新的”AI工廠”,畢竟現在不管是科技巨頭或是各國都在打造自己的人工智慧模型。
但現在的這種投資規模只有在輝達的客戶找出營利的模式後有辦法持續下去。但現在矽谷有越來越多人對於AI能否滿足這種熱切期望發出質疑。矽谷最大新創投資人之一紅杉資本的David Cahn就在自己的部落格中對圍繞在AI的投機性狂熱和靠囤積輝達晶片和先進AI就能發大財的幻想發出警告。
Cahn也看好AI未來巨大的經濟潛能,但他估計科技巨頭全部加起來需要每年產生出幾千億美金的新營收才能回收在AI基礎建設上越來越快的投資。現在像是微軟、亞馬遜雲端服務和OpenAI 從生成式AI累積所獲得的營收今年都才在幾十億美金的水準。全球最大的科技投資人之一的Prosus集團的全球AI與資料科學總監Bruno Beinat 認為科技業高管對AI能做什麼誇下海口的日子很快就要到頭了,未來的16-18個月對於AI到底能做什麼、不能做什麼會有更清醒的認識。
輝達永遠不可能變成像蘋果一樣的大眾消費商品公司。 但分析師普遍認為如果輝達要繼續成長下去需要模仿蘋果建立一個軟體平台把它的企業客戶綁在輝達的硬體上。而黃仁勳本人是一直在強調輝達不光是一家晶片公司,而是一家提供所有打造超級電腦元素的供應商,這些元素晶片、網路設備和它的CUDA軟體,這些東西能發揮讓人工智慧的應用產品和晶片”交談”的作用,也被很多人認為是輝達的秘密武器。
今年三月黃仁勳公布了輝達的NIMs 服務(Nvidia Inference Microservices):這是一組可立即幫助企業把AI用到特定行業或是領域的軟體工具。黃仁勳說這些工具可以看成是運轉大型語言模型的”操作系統”,就像是ChatGPT背後的系統一樣。黃自己是認為輝達會大規模的提供NIMs,還預測輝達被暱稱為”輝達AI公司(Nvidia AI Enterprise)”的軟體平台會成為一個非常大的事業體。輝達過去都是免費提供軟體但現在打算對採用輝達AI公司服務的企業收取每年每塊GPU 4,500美金的費用。這個服務的目的是帶進更多企業和政府的客戶,因為它們不像是大科技公司內部就有AI的專才可用。
對輝達來說,挑戰在於很多它自己的大客戶也想和軟體開發者發展出類似的關係,因此也打造了自己的AI平台。微軟希望開發者在它的Azure雲端平台開發軟體。OpenAI已經讓GPT 商店上線,在此可提供客製化的ChatGPT版本。亞馬遜和谷歌都有它們自己的開發工具,其他的新創公司如Anthropic、Mistral和等等也一樣。
當然這不是唯一輝達和自己客戶演變成競爭關係的原因。谷歌已經發展出一個客製化的AI加速晶片-TPU(Tensor Processing Unit),後來亞馬遜和微軟也都跟進了。雖然這些產品的規模都還很小,但特別是TPU讓市場的消費者不用只靠輝達。對此,輝達刻意在培養將來足以和這些大企業客戶抗衡的潛在對手以求讓自己的生態系統更多元化。
輝達已經供應晶片給像是Lambda Labs和CoreWeave這樣的新創公司,它們都是聚焦於AI服務的雲計算新創公司,它們會出租輝達晶片給外部使用。此外輝達會供應晶片給地方性的夥伴如在法國的Scaleway而不是當地的科技巨頭據點。
上一段提到的動作都是輝達在很旺的AI科技生態圈中進行加速投資活動中的一部分。僅僅過去的兩個月中,輝達參與了 Scale AI的幾輪募資,那是一家資料募到十億美金的資料辨識公司,還有Mitral-一家在巴黎的OpenAI競爭對手,已經募到6億歐元-的募資。蒐集私募業界資訊的公司PitchBook的資料顯示過去五年輝達已經進行了116筆交易。做這些除了要獲取潛在的財務收益,入股新創讓輝達能一窺下一代AI的樣貌,這對他自己接下來要開發什麼樣的產品能提供訊息。
去年得到輝達支持的AI研究實驗室Imbue的執行長邱侃軍說黃仁軍對於人工智慧趨勢的細節掌握得很透徹,黃打造了一個很大的團隊和很多人工智慧實驗室直接合作所以他能搞清楚他們在做什麼,就算這些實驗室不是輝達的客戶。也就是這種長期性的視野讓輝達站在AI浪潮的頂點。不過黃仁勳自己說過輝達在變成全世界市值最高的公司之前歷經過幾次公司差點倒掉的慘事,而且在矽谷這種割喉式的戰場,沒有一家公司是掛者免死金牌的。

Imbue的執行長 華裔的邱侃軍
二、科技巨頭的AI晶片軍火競賽還在持續中
業界很多頂尖的AI公司都賭要能創造出更複雜的人工智慧-有可能在很多事情上做得比人更好的人工智慧系統- 就要讓背後的大型語言模型更大。這就需要獲得更多資料,還要把AI系統訓練更久。OpenAI的對手 Anthropic 的執行長Dario Amodei四月初在一個Podcast中說現在市場上流通的AI模型大概要花一億美金才訓練得出來。但他又說”現在還在訓練中,今年晚點或是明年初才會發表的模型大概要花快10億美金,到了2025或是2026,會需要花到50或100億美金”。
大部分的成本都和晶片有關,而訓練大型語言模型,AI公司需要GPU以高速處理大量資料。但現在這種晶片不但缺貨,還非常貴,有最先進特色的只有一家公司做得出來,就是輝達。輝達訓練AI模型的標準配備H100晶片據說已經賣到每片3萬美金,市場上轉售的價格更是原價的好幾倍。但科技巨頭需要大量這種晶片。
臉書的祖克柏格之前說過到今年年底為止臉書打算買35萬片來進行AI的研究,即使他大量採購有優惠價,加起來也是要數十億美金。也可以不實際去買晶片就能進行訓練,但租用晶片也很貴。亞馬遜的雲計算單位可以租給客戶很大一組英代爾製造的處裡器,每小時的費用是六美金。相形之下,一組輝達H100晶片的租金是每小時一百美金。
上個月輝達公布了一種新的、稱作Blackwell的處理器設計,能以更快好幾倍的速度處理大型語言模型,而且價格和現在包括H100的Hopper系列差不多。輝達表示要訓練一個有1.8兆個參數的AI模型需要大概2000塊Blackwell晶片。1.8兆個參數是OpenAI的ChatGPT-4被認為包含的參數數量。
而買了這些晶片的公司需要一個地方來擺放晶片。臉書還有其他最大的雲計算公司-亞馬遜、微軟和谷歌-以及其他提供租借算力的公司都在加緊打造新的伺服器農場。放置這些晶片的廠方都是量身訂做的。裡面有一層層的硬碟、處理器、冷卻系統和各類電子設備和備用的發電機。
一間研究機構DellOroe 估計今年各公司會花2940億美金興建資料中心,在2020年花費在這上面的金額是1930億美金。增加的部分主要是來自於數位服務的大量增加-直播影片、大量的企業資料、社交媒體上用戶的各種收藏。但有越來越多的支出增加用在買很貴的輝達晶片和支援AI熱潮所需的其他特製的硬體。
根據市場情報公司DC Byte的資料,現在包含還在興建階段的資料中心全球有7000多間。在2015年時是3600間。這些設施現在規模也越來越大。全世界的資料中心平均面積現在是412,000平方英尺,這比2010的平均面積大了五倍。
三、晶片之外的AI第二、第三戰場
除了大部分的資金用在買晶片之外,有些AI公司正花幾百萬美金從出版商那邊想取得內容的授權。OpenAI和幾家歐洲出版商簽訂了合約要把他的新聞類內容放進ChatGPT並用來訓練AI模型。具體簽約的金額沒有公布,但彭博新聞網之前報導過OpenAI 已經答應付給Axel Springer SE,發行Politico 雜誌和商業內幕(Business Insider)的德國出版商數千萬歐元換取使用這些媒體上新刊內容的權利。OpenAI還和時代雜誌、CNN和福斯電視談過想要取得內容的授權。
其他的科技巨頭也在想辦法取得必要的網路文字紀錄來打造夠貼近人性的AI工具。谷歌已經簽了一個6000萬美元的合約從知名社交網站Reddit獲得使用資料的授權。而臉書據紐約時報報導正在內部討論是否要買下知名出版商Simon & Schuster。
不過對這波AI熱潮貢獻最大的微軟最近表示它們要嘗試另一種新的方法:微軟秀出三款較小、需要的計算力沒那麼大的AI模型。雖然微軟表示過大型語言模型還是解決各類複雜任務的標準工具例如高等推理、資料分析和理解文義。但對於某些客戶和案件來說,較小的模型就夠了。其他的公司如兩位谷歌前員工創立的Sakana AI 也聚焦於較小的模型。
專精於AI的Forester Research公司的資深研究員Rowan Curran就打了個比喻”你不是每次都需要一台跑車,有時候你只需要一台小貨車或是多功能休旅車。不需要那種大家為了應付所有情況而納入各類模型的大傢伙”。不過,現在的業內共識就是在AI的世界裡,越大就越好。但這會很貴的。